
作文対訳データベース
1. データベースの概要
このデータベースは,
- 日本語学習者による日本語作文(参考資料として,日本語母語話者による日本語作文も含む)
- 作文執筆者本人による1.の母語訳(またはもっとも楽に書ける言語への翻訳)
- 日本語教師等による1.の添削(ただし一部のみ)
- 作文執筆者・添削者の言語的履歴に関する情報
という4種類のデータを大量に収集し,相互に参照することが可能な形で電子化したものです。略称を対訳作文DBといいます。
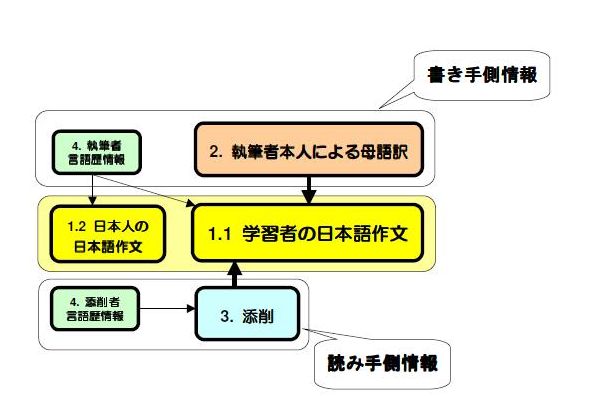
これらの情報の相互関係を概念図で表現すると以下のようになります。2.の「母語訳」は,書き手本人が書きたかった内容を母語で表現しなおしたものとして「書き手側情報」,3.の「添削」は,読み手がその文章をどのようにして読んだかを示すものとして「読み手側情報」ととらえることができます。
国立国語研究所では1999年以来,日本国内外において上記の各種データを収集し,日本語教育関係者,日本語学・対照言語学等の研究者に利用していただいてまいりました。 2009年10月には,従来未公開であったデータの整備を進めるとともに,データ抽出システムを大幅に改良しました。さらに2012年6月には,安田女子大学宮岸哲也氏のご厚意により,スリランカで収集されたシンハラ語母語話者90名の作文データ179編を掲載させていただけることになりました。現在,このwebページからご利用いただける作文データ数は1,754件となっています。
2009年のデータベース改定による変更点はこちらをご覧ください。
2. データ収集国・データ数
2009年の改定で公開するデータの収集国とデータ数は,以下のとおりです。
| 収集国名 | データ数 | 備考 |
|---|---|---|
| オーストリア | 4編 | |
| ベルギー | 30編 | |
| 中国 | 79編 | |
| ブラジル | 105編 | |
| ドイツ | 18編 | |
| フィンランド | 37編 | |
| フランス | 98編 | |
| ハンガリー | 9編 | |
| インドネシア | 80編 | |
| インド | 119編 | 執筆者1人あたり,原則として2編の作文を執筆 |
| カンボジア | 110編 | |
| 韓国 | 239編 | |
| スリランカ | 179編 | 2012年追加。執筆者1人あたり,原則として2編の作文を執筆 |
| マレーシア | 147編 | 従来,マレーシアの国記号としては”ml”を使っていたが,今後はISO3166-1に準拠し,”MY”に変更 |
| モンゴル | 42編 | |
| ポーランド | 17編 | |
| スロベニア | 12編 | |
| アメリカ | 44編 | 執筆者1人あたり,4~5編の作文を執筆 |
| シンガポール | 86編 | |
| タイ | 141編 | |
| ベトナム | 73編 | |
| 日本 | 82編 | うち,日本語母語話者のものが66編,中国語母語話者のものが9編,韓国語母語話者のものが7編 |
※上記作文数は「その国で収集された作文の数」を表していることにご注意ください。例えば,フランスで収集されたデータが98編あるからといって,98編の作文の執筆者がすべてフランス語を母語としているわけではありません。また,日本で収集されたされたデータには,日本語母語話者が執筆したものも,学習者が執筆したものも含まれています。ただし,執筆者が対訳に使用した言語(または自己申告の母語)は,ファイル名によって分かるようになっています。
※従来,一部の作文データ(中国・韓国・日本・マレーシア・タイで収集したもののすべてと,シンガポール・ベトナムで収集したものの一部)については,CD-ROM版でのみ公開をしてまいりましたが,現在はオンライン版でも公開をおこなっております。
3. 作文データ・母語訳データ数
このデータベースに収録された日本語作文データ・母語訳データは,以下のような形式で保存されています。
| ファイル形式 | 日本語データ | 母語訳データ |
|---|---|---|
| テクストファイル | 必ずあり | 基本的にあり(カンボジア,モンゴル,ベトナム※1,インド※2,で収集したデータを除く) |
| pdfファイル | 一部あり※3 | アジア諸国(インドを除く)で収集したデータのみあり |
| 手書き原稿をスキャンしたjpgファイル | ほとんどあり※4 | インド※2のみあり |
※1:プロジェクト初期(1999~2000年頃)に収集した母語訳データ(主としてアジア諸国で収集したデータ)は,当時のコンピュータではテクストファイルとして表示させることができない可能性があったため,pdfとしても保存されています。また,文字コードの関係で,テクストファイルとして保存することが自体ができなかった言語(カンボジア語,モンゴル語,ベトナム語)については,pdfファイルの形でのみ保存されています。
※2:インドで収集した母語訳データ(ヒンディー語,ベンガル語,マラティ語など)は,テクスト化自体が困難でしたので,手書きのものをスキャンしたjpgファイルの形で保存されています。
※3:プロジェクト初期(1999~2000年頃)に収集した日本語作文データは,当時日本国外のコンピュータでは日本語のテクストファイルをうまく表示できない可能性があったため,日本語データもpdf化されています。
※4:オリジナルデータが手書きである日本語作文データは,原稿用紙をそのままスキャンしたjpgファイルの形でも保存されています。執筆者本人がコンピュータ上で文章を書いている場合は,jpgファイルは存在しません。
執筆者は,先に日本語作文を書きあげてから,そのあと自分自身で母語(またはもっとも文章を書くのが得意な言語)への翻訳をしています。意訳・抄訳でなく,日本語で書いたことをそのまま母語でも書くように依頼しておりますので,母語としてはやや不自然な表現が混じっていることもあります。
4. 作文課題
このデータベースに収録された作文は,以下10種類の課題のいずれかに基づいて書かれています。
- あなたの国の行事について
- たばこについてのあなたの意見
- ワープロソフトについてのあなたの意見
- 外国からの援助についてのあなたの意見
- あなたの国の料理について
- 外国語の学習についてのあなたの意見
- あなたの国の歴史上の大きな事件
- 学校の教育についてのあなたの意見
- 大学受験についてのあなたの意見
- 仕事についてのあなたの意見
作文執筆時に執筆者が参照した課題文は,こちらをご覧ください。
このほか少数ですが,上記以外の課題に基づいて書かれたもの,どの課題について書かれたか不明なものも含まれています。
5. 添削データ
このデータベースに収録された日本語作文のうち,一部のものについては添削情報が付与されています。
添削情報は,以下2種類の形式のいずれか,あるいは両方で保存されています。
画像(jpg)ファイル
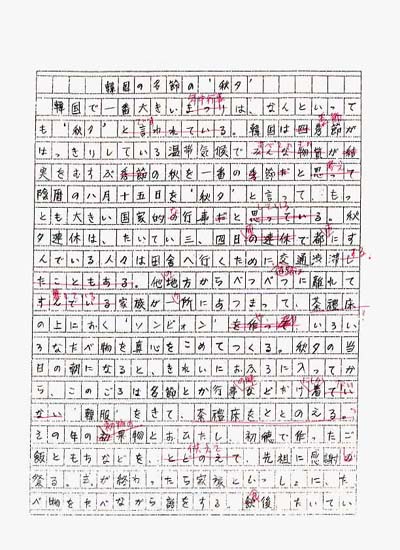
紙に書かれた学習者作文(学習者の手書き原稿のコピーまたは,テクスト化された作文を印字したもの)に対し,添削者が赤字で添削情報を書き込んだものを画像として保存したもの。
xmlファイル
置換・削除・挿入・コメント等の添削情報をxmlタグに変換し,オリジナル作文のファイルの中に埋め込んだもの。
添削情報付きxmlファイルは,スタイルシートを介してブラウザで表示させることで,手書き添削に近い出力を得ることができます。また,xmlファイルをダウンロードし,添削タグに対して,あるいは添削後の文字列に対して検索をおこなうことも可能となります。
以下に,添削情報付きxmlファイルを,スタイルシートを介してブラウザで表示させた例を示します。

現在公開している添削情報は以下のとおりです(第3期の添削情報は非公開です)。
| 期 | 収集年 | 添削対象作文 ファイル数 |
添削者属性 | 添削者母語 | 添削者数 | 1つの作文に対する 添削数 |
添削ファイル形式 |
|---|---|---|---|---|---|---|---|
| 第1期 | 2000 | 233 | 日本語教師 | 日本語/その他(添削対象作文の執筆者と同じ母語) | 43 | 1または2(2の場合,1つは日本語母語話者教師,もう1つは非母語話者教師によるもの) | jpg/xml |
| 第2期 | 2001 | 20 | 日本語教師/一般人 | 日本語/韓国語(1名のみ) | 24 | 24 | xml |
| 第4期 | 2005 | 10 | 日本語教師(経験3年以上)/日本語教師(経験3年未満)/教師志望者 | 日本語 | 43 | 43 | xml |
第1期の添削情報は,基本的には1つの作文に対し,1人の日本語教師が添削をしています。しかし一部のデータについては,1つの作文に対し,日本人教師と外国人教師(作文執筆者と同じ母語を持つ教師)が添削をおこなっています。
第2期,第4期の添削情報は,1つの作文に対し,多数の添削者(第2期は24名,第4期は43名)が添削をおこなっていますので,添削者間の添削観点の違いを比べることができます。また第4期については,添削者が「日本語教育歴豊富群(3年以上)」,「教育歴寡少群(3年未満)」,「日本語教師準備群(日本語教師になるための勉強をしているが,教育経験はない)」という3つのカテゴリに分かれていますので,カテゴリごとの比較を行うこともできます。
6. ファイル名
従来,このデータベースに掲載された作文データのファイル名は,「作文収集国」を表す英字2文字と,執筆者個人を特定するための数字3文字を基本として名づけられていました(例えば,「韓国における協力者の3人目が,日本語で書いた作文」は「kr003j」という名前になっていました)。執筆者の「母語」や「対訳に使用した言語」ではなく「作文収集国」をファイル命名のキーとしたのは,
- 母語認定が困難である場合がある(日常会話ではX語を使用しているが,文章を書く時にはY語のほうが得意,など)
- インドのような多言語国家では学習者の母語は多様であり,また実際にさまざまな言語が対訳言語として使用されてもいるため,母語または対訳使用言語をキーとすると煩雑になる
という理由があったからでした。
しかしながら,今後海外だけでなく,日本国内でも学習者の作文データを収集していくことを考えると,「作文収集国」のみを命名のキーとすることは実際的ではありません(日本国内で収集したデータについては,執筆者の母語にかかわらずすべてjpのカテゴリに入ってしまうため)。一方で,同じZ語母語話者であっても,日本国内の学習者と海外の学習者とでは習得の条件が違うため,「どの国で収集した作文か」という情報も依然として重要であると考えられます。
またこれまでは,「添削情報の付与された日本語作文」のファイル名も,添削収集時期によって命名規則が異なっており,効率的なファイル抽出が難しい状況にありました。
そこで2008年3月,データベースに収録されたデータ全体を整理しなおし,新しいファイル命名規則の下,全ファイルのリネームをおこなうことにいたしました。
新しいファイル名では,データ収集国だけでなく,「そのデータが何語で書かれているか」「執筆者が対訳言語として使用している言語はなにか」「どの作文課題で書かれているか」等の情報もファイル名内で表現されています。
新しいファイル命名規則は,こちらをご覧ください。